Reverse Engineering Prodigy, Part 1
January 15th, 2021 by Phillip Heller![]()
[ Please welcome Phillip Heller, VC&G’s newest contributor, who is a member of the Prodigy Preservation Project. Phillip will post more updates on his progress here in the future. –Benj ]
Beginning in the mid 1980s, there were a number of online “walled gardens”. Among them were CompuServe, Genie, Delphi, Quantum Link (later PC-Link, AOL, etc), and Prodigy. The latter two were interesting in that they relied on specific client software to access the service.
Quantum Link was certainly novel for the fact that it furnished a graphical online experience for the Commodore 64, and Prodigy was novel for its use of the NAPLPS graphics standard, client-side P-Code virtual-machine, and hierarchical caching. In the early 2000s, some folks nostalgic for Q-Link set out to reverse engineer it, which was a success with Q-Link Reloaded launching sometime in 2005.
It’d be interesting to do a similar thing with Prodigy: To reverse engineer the client and rebuild a mock server with enough functionality to enable those interested to relive another one of the experiences of the early commercial online world. This is the first in a many part series about doing just that.
It’s in the Patents
What is particularly interesting about reverse engineering Prodigy is that it was patented, and unlike contemporary patents, the patent is usefully descriptive. When reading the patent and contemplating a reverse engineering effort, I was very surprised to read the following:
The source code for RS 400 is provided as part of this specification. This source code can be found in the application file and is incorporated herein by reference.
So, with this knowledge, I sought out the patent application on the USPTO Public PAIR system and retrieved 2,218 pages of pre-ANSI C source code that was probably printed on a dot-matrix printer, is riddled with various patent office “received” stamps and other such things, and has a fair bit of noise precluding an easy OCR job. I have run it through OCR and produced a searchable PDF, which is somewhat helpful – more on this later.
The Steps Ahead
So, with the patent text and source code in hand, I set out to start the reverse engineering effort. Before I get too far into where I’m at, a quick description of how the Prodigy client worked:
- The client (the “reception system 400” in the patent) would be executed, would read the file
CONFIG.SMwherein it would find many configuration options including “object”, which would specify the firstPage Template Object. - That first object would be interpreted by the client and result in the display of a login screen, definition of fields for user id, password, and would bind some logic to field events through a
Program Call Segment. - The
Program Call Segmentwould invoke an application written in a language calledTBOLfor Trintex Basic Object Language (laterPALfor Prodigy Application Language; see an example here). Such applications were compiled into binary form that was executed by a virtual machine implemented in the client (look for the functiontboldrv(...)) - The program ultimately called as a result of providing credentials and clicking “login” likely invoked the TBOL verbs
connect,send, andreceiveamong others. The content of the initialsendwas some sort of login request, and the content received from the server by the call toreceivewas likely some sort of login response.
So, with that out of the way, here has been my approach to reverse engineering Prodigy:
- Get a client working. I’ve started with a version of the Windows client running under Windows 95 within qemu, which was configured to connect to tcpser, which was further configured to connect to my mock server. I chose this combination because older DOS clients fail when they don’t receive an expected response to the Hayes
ATIcommand. I’ll come back and do PRs to various projects to implement this. Subsequent conversation with Jason Overland reveals thatmodem type:NULLMODinCONFIG.SMwill remove the need for the intermediate modem emulation. - Get the client connecting to some mock server. I’m using Python for the time being for its suitability in prototyping.
- Implement the
DIAprotocol serializer and deserializer as described in the Patent and aided by the source.
I’ve done this much, and I could see a DIA FM0 header within the initial bytes sent by the client, but further encapsulated. I initially missed this in the Patent, but it is described as follows:
Link communications manager 444 is subdivided into modem control and protocol handler units. Modem control (a software function well known to the art) hands the modem specific handshaking that occurs during connect and disconnect. Protocol handler is responsible for transmission and receipt of data packets using the TCS (TRINTEX Communications Subsystem) protocol (which is a variety of OSI link level protocol, also well known to the art).
- Implement the
TCSencapsulation. This was interesting in that I found the CRC tables in the assembly to have bytes obstructed by aforementioned Patent Office artifacts. I was able to find the corresponding bytes in the binary, but it was just as easy to search the web for a few of the bytes, which reveals it is the CRC-16/X.25 that is helpfully implemented in the python crccheck module.
So, at this point I have enough to properly de-encapsulate the login request, and even send back a response that has a properly calculated CRC. But, the login request is an “application message”, likely a data structure passed to that send verb I mentioned earlier.
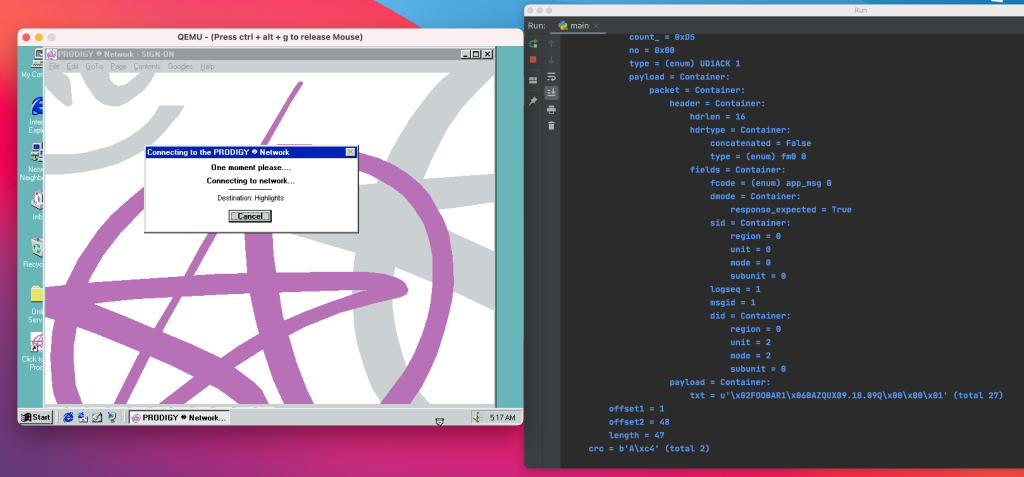
So, now there are some additional steps:
- Transcribe more of the source related to the TBOL virtual machine. Interestingly, the source does include some interactive debugging and disassembly code, sadly all conditioned on a
#definethat was certainly unset for compilation of the distribution artifacts. The transcription is necessary because it is simply too difficult to jump back and forth in the PDF, even with marginally searchable text based on poor OCR results. - Build a disassembler for the TBOL binaries, based on introspection of the TBOL opcodes and per-opcode operands.
- Determine exactly what structure the
recvcall in the login process was reading into. As the code lacks debugging symbols, it’ll probably be necessary to disassemble more TBOL programs to understand the uses of that structure such that a proper response can be constructed. - Disassemble yet more TBOL programs to implement more capabilities; e.g., the
STAGE.DATfile that existed on the client installation media was pre-warmed with certain content, like the login objects described above as well as other content expected to be popular – like weather maps and forecasts, news headlines, etc. Some of these might be possible to recreate with current content.
A Couple Shout-Outs
- Benj Edwards, Jason Overland, and Jim Carpenter, the latter of whom built the prodigy-classic-tools which parse
STAGE.DATbased on a reading of the patent and code as well. - The python-construct library, which makes quick prototyping pretty easy. I ultimately went another way, but I did re-implement some of the
STAGE.DATparsing with this, and it is certainly a more fluent way to describe such structures.
[ For more info on the Prodigy Preservation Project, check out this post. If you’d like to help the effort in transcribing the source code, let us know. We also have a working Slack group dedicated to this project for those interested in joining the effort. –Benj ]



January 18th, 2021 at 8:35 am
I just found this website through the Blues News link, fantastic site and I have it on my favourites now. Cheers
May 23rd, 2023 at 3:46 pm
Wow! Someone that actually cares about Prodigy! I’m deep diving some Prodigy stuff myself, and this post is super helpful. Thank you!