Prodigy 20 Years Ago Today
December 25th, 2012 by Benj Edwards An angle-corrected close-up view of Prodigy’s front page on Christmas 1992.
An angle-corrected close-up view of Prodigy’s front page on Christmas 1992.
Twenty years ago today, I awoke with anticipation and ran downstairs. It was Christmas morning, and I could hardly wait to open my presents.
One of those presents turned out to be a connection kit to Prodigy online service, which I had been begging my father to buy for most of the year. 1992 was the year I jumped head-first into computer telecommunications by calling local BBSes. I became fascinated with modems and wanted to explore their every possible application.
That Christmas morning, my dad was on hand to document my first experiences with Prodigy using the family Sony Camcorder. I have captured various stills from that video, and I am posting them here to share a small slice of the Prodigy experience in 1992.
Unfortunately, my computer at the time, the IBM PS/2 Model 25 (which my dad purchased new circa 1987 and later became a hand-me-down to me), came equipped with a monochrome monitor. So the glory of Prodigy Christmas 1992 in color is sadly now lost to history (well, unless someone else out there can find some color screenshots of Prodigy on Christmas 1992).
 The author, 11 years-old, trying Prodigy for the first time on 12/25/1992.
The author, 11 years-old, trying Prodigy for the first time on 12/25/1992.
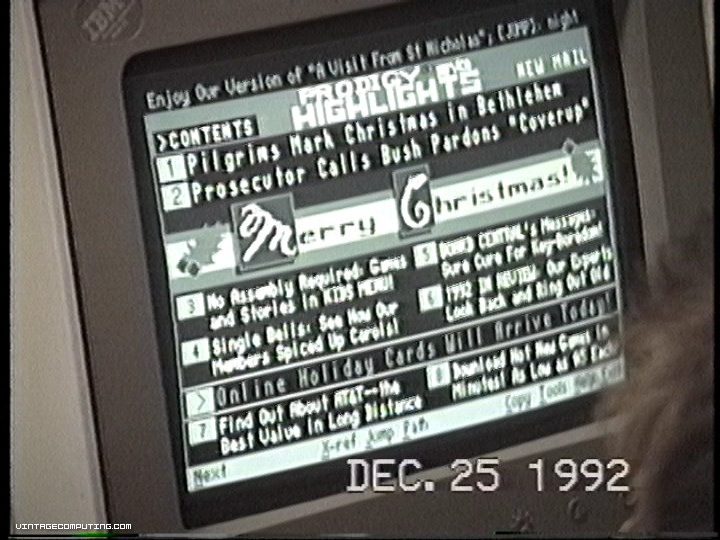 A close-up view of Prodigy’s “Highlights” front page on Christmas 1992.
A close-up view of Prodigy’s “Highlights” front page on Christmas 1992.
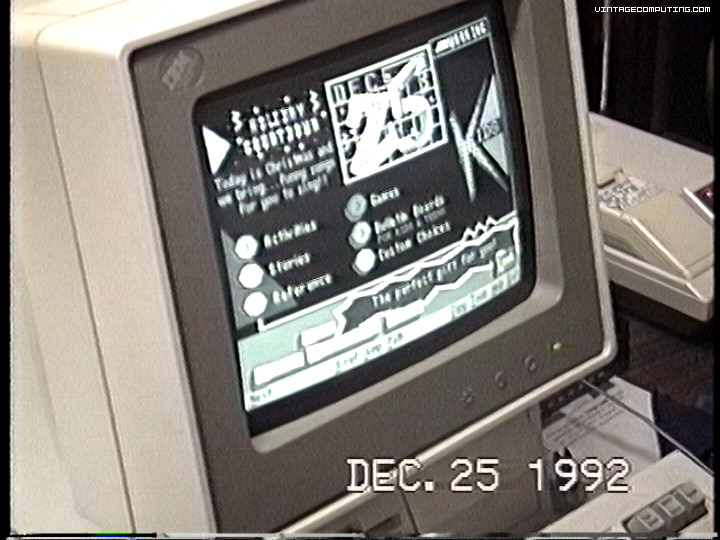 Another shot of a Prodigy holiday screen, Christmas 1992.
Another shot of a Prodigy holiday screen, Christmas 1992.
 Navigating a Prodigy path list on December 27, 1992.
Navigating a Prodigy path list on December 27, 1992.
 Benj playing MadMaze on Prodigy for the first time — Christmas 1992.
Benj playing MadMaze on Prodigy for the first time — Christmas 1992.
 Another shot of MadMaze.
Another shot of MadMaze.
Note my black Zoom modem on the desk to the right of the PC.
I have more screenshots from the video that I may be posting later by updating this page. Stay tuned.
In the meantime, have a very Merry Christmas.
P.S. Looking for Ex-Prodigy Employees
By the way, if you worked for Prodigy at some point, please let me know. I’d love to talk to you for a future project.
It would be amazing if we could figure out if the Prodigy Classic archives still exist somewhere. I haven’t dug into it much, but when I do, I suspect I’ll find an answer. Any tips or comments or memories about Prodigy in the comments will be greatly appreciated.





December 25th, 2012 at 6:18 am
An impressive document showing the pre-historic era of the Internet…. and the joy of a kid.
December 25th, 2012 at 9:27 am
The Mad Maze! Man, that brings me back.
December 25th, 2012 at 10:23 am
Is your “future project” is to archive the old Prodigy message boards, or something more ambitious, such as actually creating a telnettable Prodigy server, a la INNRevival? I was a Prodigy user from its inception in 1988 until it finally shut down at the end of 1999, so whatever you’re doing, I’m sure I’ll be very interested in the results.
December 25th, 2012 at 12:56 pm
Wow, you’re actually making me look like an early adopter! 🙂 My family got Prodigy on Christmas Day in 1991. It wasn’t much more graphically appealing for us since we used it on a 286 PC with a CGA monitor (so it ran in the high-res but monochrome mode, vs. the low-res 4-color mode).
My online exploration went in the opposite order as yours: I used Prodigy for a few months before setting out to discover BBSes.
December 29th, 2012 at 9:44 am
I didn’t like Prodigy… I LOVED IT! MadMaze was an addiction of mine. And I spent so much time on the model rocketry bulletin board.
Prodigy + IBM PS/1 = happiness
December 29th, 2012 at 1:53 pm
I had Prodigy too. I still remember my ID! Haha. I remember using it in EGA and then VGA in DOS on 2400 internal modems and IBM PS/2s (30 286 10 Mhz and P70 386) I hated its blue screen! Ha, like Windows.
MadMaze in Internet Explorer: http://d1144651.mydomainwebhost.com/MadMaze2/
December 29th, 2012 at 10:45 pm
A couple of weeks ago, for some unknown reason, I was all about Prodigy. I bought Prodigy install disks (5.25″, DOS) on eBay, after a bit of searching downloaded a Windows version online, and even started looking at an old copy of the Prodigy Reception System (the client software) from the backup of an old PS/1 system. I started examining the infamous STAGE.DAT files, messing with the CONFIG.DAT files and taking screenshots, which are available at http://flic.kr/s/aHsjDfuNsk . Nothing too interesting there yet, mainly because the STAGE.DAT files I have are mostly clean; I need ones from more active installs. Maybe I’ll be able to find more old backups. When I get a free day I’m also going to write a simple script to suck up all the NAPLPS (the graphics) out of the STAGE.DAT files and perhaps even slightly reverse engineer some of the objects trapped inside. I’d love to talk to some former Prodigy engineers but the Prodigy alumni groups on LinkedIn and Yahoo don’t seem too interested in outsiders. 🙁
December 30th, 2012 at 2:33 pm
Very cool, Jim. I’ve started digging through my archives for STAGE.DAT files that I may have lying around. I suspect that I won’t find any (I was on Prodigy during a time before several HD crashes that lost everything), but you never know.
I’d be interested in how you extract the NAPLPS data, if you’d like to explain it in an email. A script would be a great idea.
January 3rd, 2013 at 3:28 am
you could afford prodigy but NOT a color display? 😀
January 20th, 2013 at 10:18 pm
Hi, I worked at the Prodigy headquaters in White Plains back in around 1987 and 1988. The location was 445 Hamilton Ave, right behind Sears. They had something like 5 floors in the building. I had a Prodigy photo ID card-key (still have it), with access to practically every room there. I did security there while in college.
It was a memorable experience to walk the floors and have access to the giant mainframe room and walk right by the command center, with its giant screen in the middle surrounded by smaller ones. It was like mission control in Houston! To witness the massive collaborative effort of all the different departments, working in sync together, was amazing. Great people too. We even got to mess around on the trial PC’s in the hallways as they were putting stuff out. Much like today, there were rooms where they put together graphics, sounds, etc. Incredible.
And to realize that it was the birth of it all, makes those memories unforgettable. I am still facsinated by the how primative the interface looks now.
February 16th, 2013 at 4:13 pm
I’ve managed to scrounge up an old STAGE.DAT file from 1996 – is there a utility to extract the NAPLPS graphics from it?
February 18th, 2013 at 10:19 am
Asterisk,
There’s no utility yet, but Jim Carpenter has been working on one. If you could, please email any STAGE.DAT and CACHE.DAT files you can find to me (email link in upper-right of every VC&G page), and I’ll pass them on to Jim. We are collecting them at the moment.
Regards,
Benj
April 15th, 2013 at 1:08 am
In January 1994, there was…an infomercial, I guess…that was played just like a game show. It was called “The Prodigy Challenge”, hosted by Peter Tomarken with Charlie O’Donnell as announcer.
http://www.youtube.com/watch?v=R5XcvMnjuOg
(If the link doesn’t show up, search YouTube for “Prodigy Challenge”.)
January 9th, 2014 at 8:48 pm
Did you ever get any info on where the BB archives were located, if they were backed up anywhere? I would give an arm and a leg to see old posts when i was a kid
January 12th, 2014 at 5:45 pm
No, Felicia, I have not found the Prodigy archives. But I haven’t looked very hard either. Perhaps it’s something I could look into more soon.
May 3rd, 2014 at 6:17 pm
Would love to find the old archives. There are some historically significant materials to be found there, particularly in the area of internet activism.
July 12th, 2014 at 11:00 pm
Reminds me of when I got my Amiga 500.
I was such a lil wannabe nerd.
July 14th, 2014 at 11:56 am
I just read Benj’s Atlantic update on Jim Carpenter’s work, and boy am I excited. I recently went through some of my paper files, and found a few printouts of bulletin board posts (where I spent most of my time). If old archives existed we would gain so much, as so much was lost.
July 14th, 2014 at 3:07 pm
I had Prodigy since it started but my old computers are in storage and not accessible anytime soon. I still have my Prodigy.net email thru AT&T dsl service.
I just dug out my Prodigy Internet Version 5 copyright 1999 for Windows and Macintosh CD. It had my original user ID FFF*** card inside protective sleeve.
I would be glad to mail you the CD if you need it.
November 10th, 2014 at 12:31 am
Does anyone else remember the Heinlein Forum on Prodigy? I don’t remember if I ever posted there, but saw it and some friends did.
December 6th, 2014 at 7:16 pm
My family and I were on Prodigy for a couple of years until they jacked the prices…the forums were filled with people calling them “Fraudigy” and a lot of people jumped ship. We were among them. We tried National Videotex Network for a few months (it sucked) and then AOL, where we stayed for about ten years!
December 26th, 2014 at 4:58 pm
I have lost all my contacts. Moved and to go Verizon. CAN I GE MY OLD CONTATS TRANSFRED SEND TO Ann.kubicek1@veizon.net
January 18th, 2016 at 10:37 pm
Looks like I am not the first Ultima Dragon to be interested in this project! Most of the first three years of our history, the club that became the UDIC in 1994, are locked up in Prodigy archives. I’m also interested in any of the Bulletin Board posts or the UG mails if they still exist. Keep an eye out for terms like Drunken Stupor, GC, G@C, Wingers, Inner Circle, Upper Circle, etc., or anything with “_____ Dragon”. I have some accounts from older Dragons but most of them are shrouded in fuzzy memory. Here’s hoping some can be recovered before the entire service becomes NMPRed.
March 2nd, 2020 at 10:31 pm
I never worked there but was in other areas. Prodigy was an early try at a Graphical Internet, which it did by Client and Server possessing each copies of an Archive of certain Graphics called by a “script like” language. With this, Prodigy “forewent” the necessity to transfer large amounts of Graphics online! Of course, it was only needed until the Technology caught up with the Huge appetite for Speed and Sizes required by True on the fly Graphics! That is where I was at the Prodigy heyday. Working for Western Digital solving the problems allowing the Birth of The World Wide Web! The last coffin nail for Prodigy! It is funny indeed that I find myself wanting to see again the old Prodigy Graphics. I don’t want to live there though!
April 21st, 2020 at 1:07 pm
I loved Prodigy. I had it in the early 90’s through Netcom. My favorite game was
The Thinker, a logic type game. I have been trying to find it for years. But with such a common name (Thinker), I have had no luck.